The Language We Forgot We Could Speak
Author: Ryan Yen
Before “computer” meant a machine, it meant a person.
In 1945, approximately 100 women worked as “human computers” at the University of Pennsylvania, calculating artillery firing tables for the U.S. Army (Light, 1999). Each ballistics trajectory required hours of hand calculation using mechanical desktop calculators. The women worked in teams, passing intermediate results down rows of desks like an assembly line of arithmetic.
These women stood between scientists and machine. A physicist would hand them an equation, some beautiful, ambiguous thing full of implicit assumptions and contextual shortcuts. The “computer” would translate this into steps.
When ENIAC arrived in 1945, something interesting happened. The Army didn’t fire the human computers but selected six women to program the machine.
But “program” is almost the wrong word. There was no programming language.
The ENIAC programmers had to physically rewire the machine for each calculation, setting thousands of switches and plugging cables into patch panels, but soon after, punched media allowed programs to be prepared separately and loaded in. Programs were entered using punched cards or paper tape, strips of paper with holes punched in patterns to represent instructions.

These “computers” were still doing the same job their predecessors had done: translating intention into mechanism. The only difference was that now the mechanism was electronic instead of mental.
This arrangement—humans as the flexible interpreters between messy intent and rigid machinery, lasted for about a decade. Then something changed. Not all at once, but gradually, so gradually that nobody noticed what was being lost.
Part II: The Cultural Shift
It started with a reasonable question: why should humans do the translation at all?
Grace Hopper had an answer. In 1952, working at Remington Rand, she created the A-0 System, generally considered the first compiler. Her colleagues were skeptical. “Nobody believed that [we] had a running compiler and nobody would touch it,” she later recalled. The idea seemed absurd, that you could write instructions in something closer to mathematical notation, and a program would translate them into machine code.
FORTRAN followed in 1957, developed by John Backus’s team at IBM. And with FORTRAN came a transformation that’s easy to miss from our vantage point today. Programmers weren’t just translators anymore. They became authors, writing in languages bound by strict, unforgiving rules. A missing semicolon would break everything. A misplaced word rendered the whole thing meaningless.
This trade-off, surrendering the flexibility of natural communication for the precision of formal notation, wasn’t inevitable. It was a choice, one that came to define programming for seventy years. A language had to be unambiguous, complete, verifiable. A program had to mean exactly the same thing to everyone who read it.
Variation was error. Flexibility was weakness.
There were rebels though. In 1966, Jean Sammet published “The Use of English as a Programming Language” (Sammet, 1966), imagining machines that might learn human language.
Thirteen years later, Edsger Dijkstra wrote “On the Foolishness of ‘Natural Language Programming’” (Dijkstra, 1979). His argument was precise. Natural language is ambiguous. Computers need unambiguous instructions, the details that natural language could not provide. Considering English as a programming language wasn’t just technically hard. It was a category error.
With the machines that existed in 1979, he was right. Those machines were rigid, literal, unforgiving. They couldn’t infer. They couldn’t fill gaps. Formal languages weren’t a preference; they were a necessity. And we still use formal languages today because they provide the precise details about requirements that we need.
But Sammet wasn’t wrong either. She was early.
For seventy years after, “programming language” meant a language for computers, not for humans. We kept climbing the ladder of abstraction, from machine code to assembly to FORTRAN to Python, each rung promising to be more readable, more intuitive. But each rung introduced its own concepts, its own rules, its own ways of breaking. The more “natural” it tries to be, the more deceptive it becomes, as it is still formal and rigid.
And as Dijkstra predicted,
From one gut feeling I derive much consolation: I suspect that machines to be programmed in our native tongues […] are as damned difficult to make as they would be to use. (Dijkstra, 1979)
Part III: The Dream Deferred
Then, all at once, something shifted.
Large language models arrived with a strange new capability. You could describe what you wanted in plain English, and they would generate code. LLMs suddenly became the bridge between natural language and working programs.
The headlines went wild:
“No Code Required.”
“The End of Programming.”
“AI Will Replace Developers.”
But something odd happened. The instructions you gave the model weren’t part of the program. You were talking to a separate machine, asking it to generate formal code on your behalf. The dream of natural language programming was about writing programs in natural language. This was different. This was writing natural language instructions to a translator that would then write the formal code for you.
But because natural language isn’t the program itself, programmers still need to read, learn, and understand the formal code that gets generated. Here’s the pattern I’ve seen play out:
A manager wants an application.
A programmer, Alicia, describes it in English.
The LLM produces code.
But the code doesn’t quite work, there’s a bug, an edge case the prompt didn’t specify.
She needs to debug it.
But to debug it, she needs to understand it.
And to understand it, she needs to learn… programming.
The thing she thought she’d bypassed.
The LLM moved the barrier, but it didn’t remove it. In some ways it made things worse, because now you need to understand not just programming, but what the LLM did, which is far less transparent than code you wrote yourself.
So here we are, two years into the LLM era, and most people still can’t program.
The formal bottleneck remains.
Part IV: The Possibility We Overlooked
But what if we’re asking the wrong question?
The LLM sits outside the program, translating natural language into formal code. But what if the natural language could be part of the program itself? What if the LLM wasn’t a separate translator, but an interpreter woven into execution, reading informal specifications alongside formal logic, making sense of both as the program runs?
We struggle to imagine this because seventy years of compiler-thinking has trained us to believe programs must be completely formalized before they execute. But that’s a historical accident, not a law of nature.
Think back to the human computers. They didn’t all use the same notation. A physicist’s calculator developed shorthand for physics equations. A statistician’s calculator developed patterns for statistical work. Each created their own language suited to their domain. The machine didn’t care, because the human interpreter could handle the variation.
When we built automatic compilers, we lost this flexibility. A compiler understands one language, spoken perfectly. Everyone must speak the same way.
But an LLM isn’t a compiler in the old sense. It’s something stranger and more flexible. It can understand multiple notations. It can infer intention across contexts. It can hold both formal and informal representations simultaneously.
This opens a different possibility: users don’t need to learn “the language.” They express themselves in whatever notation makes sense, of course formal code where precision matters, natural language where intent is enough, equations, sketches, examples, whatever…
and the system interprets it during execution.
We call this way of program, Semi-Formal Programming.
The crucial difference from prompting is that these expressions are the program. They’re not prompts to an AI sitting outside. They’re not completely formal code to a compiler. They’re the program itself, written in whatever notation feels natural, mixing formality and informality freely.
The system assigns semantics to each piece. Once a notation has semantics, reusing it produces the same behavior. The program becomes a living document where some parts are precise and some parts are sketches, and both execute.
Let’s see what semiformal program might look like in practice:
Consider a marine biologist modelling coral bleaching. Today her work lives in three places: equations in a paper, temperature data in a spreadsheet, Python scripts she half-understands.
In a semiformal system, she writes in her domain’s notation:
1
thermal_stress[t] = Σ(SST[t] - MMM) for days where SST > MMM + 1°C
that notation gets parsed and assigned a specific computational meaning. thermal_stress is an accumulator with a conditional filter, MMM is Maximum Monthly Mean, a climatological baseline that needs a data source.
Each piece has semantics she can inspect. She clicks MMM and sees where it comes from, what it’s bound to, whether she wants to override it with local measurements. When she changes the bleaching threshold from 4 to 6 DHW, the system traces dependencies and recomputes only what’s affected.
Her notations are the program.
The same principle applies across domains.
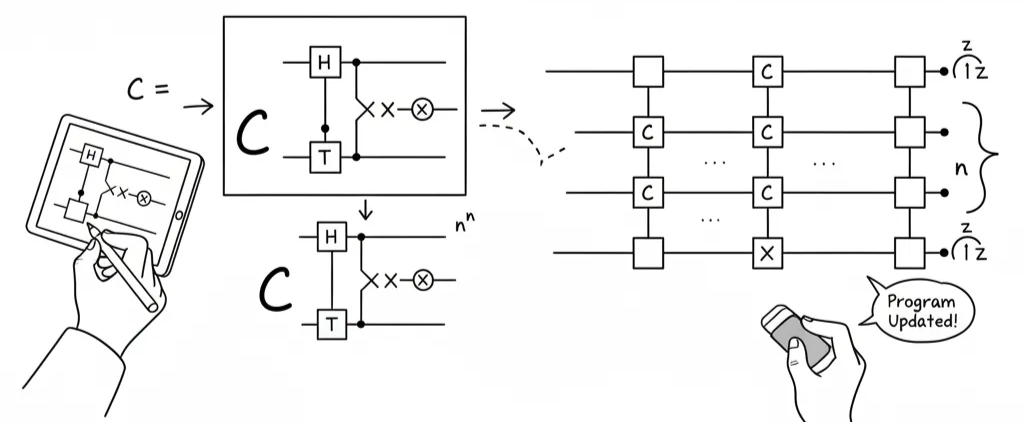
A quantum computing researcher is sketching a circuit. She doesn’t write Qiskit or Cirq. She draws: a horizontal line for a qubit, a box with “H” for a Hadamard gate, a vertical connection with a control dot for a CNOT.
She draws a small subcircuit and writes C = next to it. That becomes a definition.
Later, when she draws a box labeled “C,” the system recognizes the subcircuit she defined, with its semantics intact and expandable to the same gates on the same qubit topology.
She adds an ellipsis with a superscript n to indicate repetition across qubits. It’s informal shorthand, the kind physicists scribble on whiteboards, but the system parses it:
this pattern repeats with parameter n, inferred from context.
When she modifies the circuit, she doesn’t edit generated code but erases a gate and draws a different one. The implementation updates to match and propagate changes downstream.
Her sketches are the program.
These two examples show the core idea of semiformal programming that the gap between human expression and machine execution isn’t bridged by compilation, but by interpretation.
The biologist’s equation and the physicist’s sketch aren’t converted into Python or Qiskit, they remain as written, in their native notations. The system doesn’t ask them to formalize everything upfront. Instead, it assigns computational meaning to whatever they write, in whatever form they write it, and executes that meaning directly. The notation is the program, and the program adapts to the user’s language, keeps iterating reactively, and remains a living artifact.
Part V: The Hard Questions
While these envisioned scenarios get the best of both worlds, they also share the worst of both worlds.
Traditional software has bugs, but the bugs are deterministic. Run the same input twice, get the same wrong output twice. Debug by tracing execution, find the line that’s wrong, fix it. Semiformal systems don’t work this way. The same input might produce different outputs based on subtle context variations. The interpretation layer might “drift” as the underlying models update. The behavior you tested last month might not be the behavior you get today.
For low-stakes applications, casual data analysis, personal organization, creative exploration, this is probably fine. We tolerate uncertainty in lots of tools we use daily.
For high-stakes applications, the places where software failures harm people or crash markets, this is a serious barrier.
Regulation should be focused on the right place: the artifact that a domain expert edits is not the same artifact that executes on the machine, and the interpretation layer between them is where risk concentrates. Medical device software requires formal verification beneath any semiformal interface. Aviation systems still use rigid languages for flight-critical code. Financial systems enforce deterministic test suites that run on every model update.
This is why formal languages are not going away (Martin, 2009). The most important development wasn’t about notation at all. It was about verification. Teams learned, sometimes the hard way, to write formal test specifications alongside their semiformal programs. Even if the program itself is sketchy and interpretive, the tests are precise. The interpretation layer can drift, can be nondeterministic, can update with new model versions. But the tests catch it.
The formal verification layer beneath the semiformal interface is always required to guarantee safety properties regardless of how the interpretation layer behaves. Either way, the path to adoption in safety-critical domains will be long, and it probably should be.
The collaboration problem might be even thornier. I’ve been describing semiformal programming as liberating, as freeing individuals to express computation in their own terms. But “your own terms” and “terms we can share” are in tension.
Traditional programming languages were designed for shared understanding. A Java program means the same thing to everyone who reads it. The syntax is fixed. The semantics are specified. Two programmers can collaborate on code without ever meeting, because the language itself enforces common ground.
Semiformal systems could fragment this. If my physics model uses my idiosyncratic notation and your physics model uses yours, how do we combine them? What if my program offended you? How do we even have a meaningful conversation about whether our models are consistent?
We have a hypothesis about how this might resolve. Sociolinguistics had already studied exactly this kind of convergence. When people share a goal, they naturally adjust their communication styles toward each other. Not because anyone mandates it, but because mutual understanding requires it (Giles et al., 2023). When groups engage in shared activity over time, they develop common vocabulary and negotiated conventions that emerge from use rather than from top-down standardization (Wenger, 1998). Members converge not to lose individuality but to enable communication (Eckert & McConnell-Ginet, 1992).
I suspected something like folksonomy would happen (Trant, 2009), the way users on early social platforms organically converged on shared hashtags without anyone dictating which tags to use. A community would gravitate toward common marks simply because shared marks are more useful than private ones.
I hope that gradually, domain by domain, shared patterns will crystallize. Marine biologists working on thermal stress developed shared conventions for expressing bleaching thresholds. It happened the way any community develops shared slang: through use, repetition, and the slow pressure of needing to be understood.
Corporations can publish what amounted to “semiformal language protocols,” internal style guides that defined which notations carried which computational semantics within their organization.
Part VI: Semiformal Software and Execution
I find this future exciting and terrifying in equal measure.
We could be looking at another seventy years of work to make this reliable, secure, and genuinely pleasant to use. The entire ecosystem would have to shift. It’s no longer just the compiler designer asking “how do I build a language people can use?” but also the tool designer asking “how do I build an environment where people can program semiformally?” That’s a different problem—harder in some ways, as it requires time to understand how to better support the user experience, and it is not tangible.
But it’s the problem that follows from taking seriously the idea that programming should be expression, not conformance. If the user’s notation is the program, then the user is always, in some sense, a language designer.
And I hope that can also bring us to malleable software.
Where we build software that is malleable and highly customizable. Applications built with semiformal code wouldn’t be frozen artifacts but would leave intentional room for interpretation. Data processing libraries would not have to preassume how users’ data should be formatted; visualization libraries would not have to decide layout from common heuristics but could infer from actual user data; the search box could support semantic search by concept, not just keyword; the table could have grouping and sorting based on the user’s data structure rather than alphabetical order…
I’m also imagining something like semiformal execution.
Not compilation from informal to formal to machine code, but direct, continuous interpretation of the semiformal artifact itself. The debug console might have a mixture of code errors and LLM reasoning, where the reasoning steps are editable and can steer back the model.
Epilogue: The Language We Never Stopped Speaking
The human computers of 1945 knew something we’ve forgotten: that the point was never the notation. It was the thinking. The notation was just a way to make thinking executable. We taught humans to speak like machines because we had no choice. The machines were rigid, literal, unforgiving. They couldn’t meet us halfway.
That constraint is lifting. Not completely, not overnight, but meaningfully. The question now isn’t whether machines can interpret human intent with some flexibility. They already can. The question is whether we’re willing to build on that, to do the hard work of combining informal expression with formal guarantees, even when the path isn’t clear.
The real obstacle is cultural, not technical.
Grace Hopper had a clock on her wall that ran counterclockwise. “Humans are allergic to change,” she said. “They love to say, ‘We’ve always done it this way.’ I try to fight that.” The allergy she diagnosed hasn’t gone away. If anything, seventy years of programming tradition has made it chronic.
Maybe
Maybe it’s time to see what happens when we get to speak our own languages.
References
Dijkstra, E. W. (1979). On the foolishness of “natural language programming.” EWD667.
Eckert, P., & McConnell-Ginet, S. (1992). Think practically and look locally: Language and gender as community-based practice. Annual Review of Anthropology, 21, 461-490.
Giles, H., Edwards, A. L., & Walther, J. B. (2023). Communication accommodation theory: Past accomplishments, current trends, and future prospects. Language & Communication, 93, 3-12.
Light, J. (1999). When computers were women. Technology and Culture, 40(3), 455-483.
Martin, R. C. (2009). Clean Code: A Handbook of Agile Software Craftsmanship. Pearson Education.
Sammet, J. E. (1966). The use of English as a programming language. Communications of the ACM, 9(3), 228-230.
Trant, J. (2009). Studying social tagging and folksonomy: A review and framework. Journal of Digital Information, 10(1).
Wenger, É. (1998). Communities of Practice: Learning, Meaning, and Identity. Cambridge University Press.
Comments